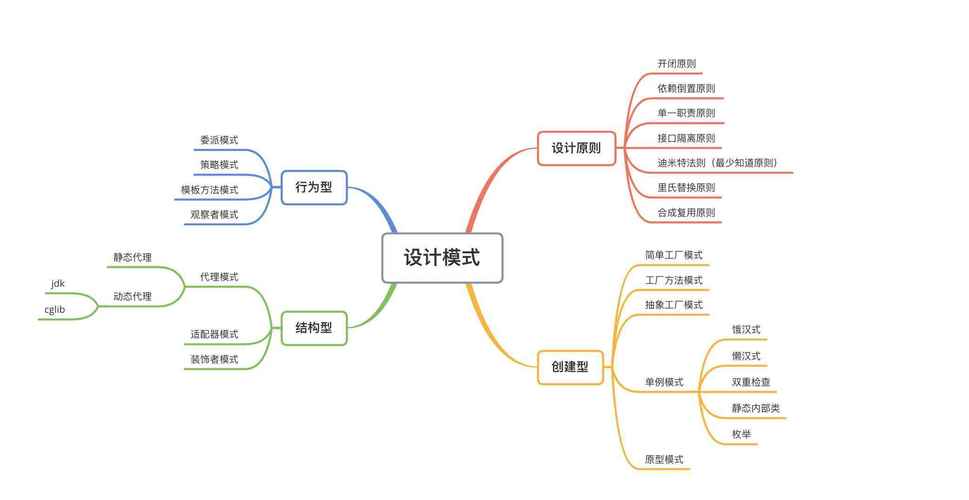
一、字符集和字符编码
1.1 基本概念
- 要解释乱码的由来,我们需要先搞清楚两个非常重要的概念:
字符集(Character set)和字符编码(Character encoding)。
- 字符集:首先字符(Character)是各种文字和符号的总称,也包括图形符号、数字等。字符集(Character set)顾名思义也就是
字符的集合。
- 字符编码:也称字集码,是
把字符集中的字符编码为指定集合中某一对象的一种方案,通俗的说就是一种映射关系。
- 常见字符集:ASCII(美国信息交换标准码)、Unicode(万国码、统一码)、GB2312(信息交换用汉字编码字符集)。常见字符编码:UTF-8、UTF-16、GBK、GB2312等。
- 你会发现二者存在交叉,这也是网上的资料容易把这两者混淆的重要原因之一。为了更方便理解,可以这样认为:字符集是一个大的集合,包含了各种字符;而字符编码则是将字符集中的字符进行编码,使得计算机能够理解和处理。
1.2 常见字符集
1. ASCII
- ASCII(American Standard Code for Information Interchange)是基于拉丁字母的一套计算机编码系统。它主要用于显示现代英语,其中共有128个字符,包含了所有的大写和小写字母,数字0到9、标点符号, 以及在美式英语中使用的特殊控制字符等。
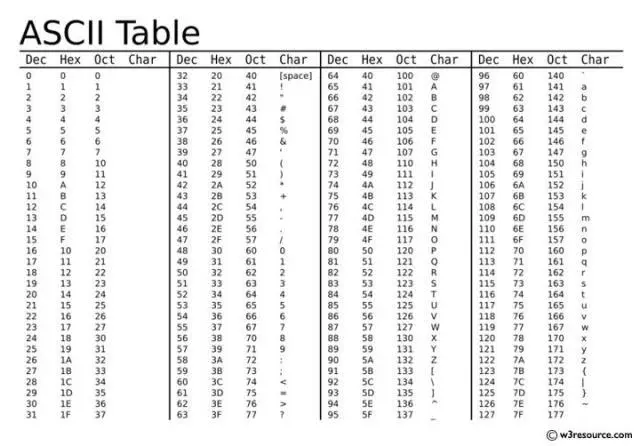
- 举个例子,字符A对应的 ASCII 码为65;数字字符0对应的ASCII码为48:
1
2
3
4
| >>> ord('A')
65
>>> ord('0')
48
|
- ASCII 的缺点很明显,它只包含128个字符,仅适用于英语和一些常见的符号。它无法表示非拉丁字母、特殊符号和其他语言的字符,如中文、日文和俄文等。
2. Unicode
- Unicode 和 ASCII 一样,也是用一系列数字来表示字符,这些数字被称为
码点(code points)。相比与 ASCII,它对世界上大部分的文字系统进行了整理、编码,因此也被称为万国码、统一码,并成为了计算机领域最通用的字符集之一。
- 我们可以通过很多方式查看一个字符的 Unicode 码点,例如在 Python 中使用 ord() 查看”雷”这个字符的码点:
- Unicode 码点更常见的表示方式是十六进制,也就是将十进制的
38647转为十六进制后的96f7:
- 在 Python 环境下,Unicode 字符的转义序列是用
\uxxxx来表示的,其中的xxxx就是这个字符的码点(code points)。
1.3 常见字符编码
- 前面说的 Unicode 虽然统一了全世界字符的编码,但没有规定如何存储。这样就会导致出现了各种各样的存储方案,也就是所谓的字符编码。为什么 Unicode 不统一规定都用两个或四个字节表示?又或者一步到位用八个字节甚至更大的字节来保存,这样不就不怕容量不够了吗?原因显而易见,一旦这么规定,那么每个英文字母前都必然有很多位是0,因为所有英文字母在ASCII中都有,都可以用一个字节表示,剩余字节位置就要补充0。这样会造成极大的空间浪费。
- 为了解决这个问题,就出现了一些中间格式的字符集,他们被称为通用转换格式,即 UTF(Unicode Transformation Format),其实也就是我们所说的字符编码。常见的 UTF 格式有:UTF-7、UTF-7.5、UTF-8、UTF-16 以及 UTF-32。
1. UTF-8
- 我们最熟悉的字符编码方案之一,使用可变长度字节来储存 Unicode 字符,什么意思呢?例如 ASCII 字母继续使用1字节储存,希腊字母等使用2字节来储存,常用的汉字使用3字节储存,辅助平面字符则使用4字节。
- 他的优点和缺点都是由于其长度可变的特点带来的。优点是可以节省大量空间,缺点是对于排在前面优先纳入的文字,就会优先使用1字节、2字节存储,对于后纳入的文字可能就需要3字节或者4字节存储,这也会导致空间的浪费。例如对于常用的汉字,在 UTF-8 中就是采用3字节进行编码的。
2. GB2312
- 前面说了对于常用的汉字在UTF-8中是用3个字节来存储的,但是实际上,如果有一种只包含中文和 ASCII 的编码的话,就不需要使用3个字节,可能2个字节就够了。比如在我们国内浏览内容的时候,是很少见到一些偏僻国家的语言的。
- 因此,为了进一步节省空间,中国国家标准总局在1980年制定了16位字符集
GB2312,收录有6763个简体汉字,682个符号,共7445个字符,适用于简体中文环境,属于中国国家标准,通行于大陆。
2. GBK
- 由于 GB2312 不兼容繁体中文,其汉字集合过少,在1995年,中华人民共和国全国信息技术标准化技术委员会指定了
GBK(汉字内码扩展规范)即”国标”,适用于简繁中文共存的环境,为简体 Windows 系统所使用,向下完全兼容GB2312。
- 缺点是GBK不属于官方标准,很多搜索引擎都不能很好地支持GBK汉字,我在使用 Windows 传输文件时也经常出现乱码的问题,需要手动调整一下编码方式。
2. GB18030
- 2000年制定,32位字符集,收录了27484个汉字,同时收录了藏文、蒙文、维吾尔文等主要的少数民族文字。收录了所有你能想到的文字和符号,属于中国最新的国家标准,但是目前支持它的软件较少。
二、乱码
2.1、乱码的由来
- 上面扯了那么多,现在回到正题,乱码到底是怎么产生的?其实很简单,一句话总结就是
字符串编码和解码之间的不匹配,导致字节序列被解释成不同的字符。
- 比如说: 我使用UTF-8对”皓哥”两个字进行编码,得到了字节序列
b'\xe7\x9a\x93\xe5\x93\xa5'(在 Python 的字符串中,\x 表示一个十六进制转义符):
1
2
| >>> u'皓哥'.encode('utf8')
b'\xe7\x9a\x93\xe5\x93\xa5'
|
- 由于UTF-8中常见的汉字都使用3个字节存储,所以皓哥一共占了6个字节。其中
\xe7\x9a\x93表示”皓”,\xe5\x93\xa5表示”哥”。
- 接下来我们用GBK对”皓哥”两个字进行编码,更准确的说,是对字节序列
b'\xe7\x9a\x93\xe5\x93\xa5'进行解码”:
1
2
| >>> b'\xe7\x9a\x93\xe5\x93\xa5'.decode('gbk')
'鐨撳摜'
|
- 哪还是什么”皓哥”,’鐨撳摜’是什么哥,我也不知道。并且我们注意到解码之后由原先的两个字变成了三个字,这是因为UTF-8中汉字是由3个字节储存,而GBK中汉字是由2个字节存储的。也就是说,我们的字节流解码时被拆分成了
\xe7\x9a、\x93\xe5以及\x93\xa5。
1
2
3
4
5
6
| >>> b'\xe7\x9a'.decode('gbk')
'鐨'
>>> b'\x93\xe5'.decode('gbk')
'撳'
>>> b'\x93\xa5'.decode('gbk')
'摜'
|
2.2、常见乱码复现
- 有了上面的预备知识,我们就可以尝试探寻一下我们见过多次的乱码们了。在学生时代我们偶然在C语言课堂上看到的一堆的烫烫烫屯屯屯时,只顾着哈哈笑了,今天我们就来详细探索一下它们出现的原因。
- 烫和屯
- 第一步,分别使用UTF-8和GBK对字符进行编码:
1
2
3
4
5
6
7
8
| >>> u'烫'.encode('utf8')
b'\xe7\x83\xab'
>>> u'烫'.encode('gbk')
b'\xcc\xcc'
>>> u'屯'.encode('utf8')
b'\xe5\xb1\xaf'
>>> u'屯'.encode('gbk')
b'\xcd\xcd'
|
- 第二步,查找编码结果对应的字节序列在计算机中的有没有特殊含义。经过查找,发现在 Windows 环境下,未初始化的栈内存会初始化为十六进制值
0xCC,而未初始化的堆内存则会初始化为十六进制值0xCD,刚好是烫和屯的GBK编码结果。
- 所以出现”烫”和”屯”这样的乱码就很好理解了,总结一下就是由于”烫”和”屯”的GBK编码和 Windows 环境下和未初始化的栈和堆内存的初始化值一样了,导致解码时出现乱码。
- 锟斤拷
- 第一步,一样使用UTF-8和GBK对字符进行编码:
1
2
3
4
| >>> u'锟斤拷'.encode('utf8')
b'\xe9\x94\x9f\xe6\x96\xa4\xe6\x8b\xb7'
>>> u'锟斤拷'.encode('gbk')
b'\xef\xbf\xbd\xef\xbf\xbd'
|
- 第二步,查找编码结果对应的字节序列在计算机中的有没有特殊含义。经过查找,发现其编码都没有特殊含义。所以得换个思路,由于很多时候乱码都是由于使用UTF-8进行编码使用GBK进行解码导致的。所以我们可以先逆向推理出什么字符在通过UTF-8编码后,通过GBK解码会得到二进制序列
b'\xef\xbf\xbd\xef\xbf\xbd':
1
2
| >>> b'\xef\xbf\xbd\xef\xbf\xbd'.decode('utf8')
'��'
|
1
2
| >>> u'��'.encode('utf8').decode('gbk')
'锟斤拷'
|
Tips:
Unicode 中的 \uFFFD(十进制为 65533)用于表示无法识别的字符或者编码错误。在最初的 Unicode 规范中,只使用了 16 位来表示每个字符,即取值范围为 0x0000 到 0xFFFF。当时,Unicode 中留了几个位置作为保留位置,供未来用来扩展字符集。后来发现,16 位无法覆盖全世界的各种语言和符号,所以 Unicode 开始使用 21 位来表示每个字符,即取值范围为 0x000000 到 0x10FFFF。但是,为了向后兼容,Unicode 仍然保留了之前的字符编码值,并将 0xFFFD(即 1111 1111 1111 1101)作为未知字符或编码错误的占位符,可以看作是 16 位编码时的“保留位置”的替代。总的来说,选择 0xFFFD 作为无效字符的编码值,主要是为了向后兼容,同时也方便对旧版 Unicode 进行处理和转换。
- 经过上面的分析已经知道锟斤拷出现的原因了,总结一下就是使用UTF-8方式进行编码时遇到了多个 Unicode 占位符,并且还使用了GBK的方式进行解码,这时就会出现我们熟悉的锟斤铐了:
1
2
| >>> (u'\ufffd'.encode('utf8')*10).decode('gbk')
'锟斤拷锟斤拷锟斤拷锟斤拷锟斤拷'
|